LaTeX Diff?
https://github.com/gaulinmp/latexdiff
This guy has many interesting things. A cool github collection, and many good working papers.
https://github.com/gaulinmp/latexdiff
This guy has many interesting things. A cool github collection, and many good working papers.
Nowadays, we have a lot of cores in the CPU. But we cannot make any good use of it unless we program in multicore.
Say we have thousands of SEC filings to process every year; we write a function to collect data from it. For most filings, it works just fine. But for a small group of filings (8 out of 8000+ in 2005, for my data set, as an example), it runs with no end. 10 hours later, the process for this filing is still stuck somewhere. As Obama once famously (and maybe unfairly) said, “Eight is enough.” (It was unfair, according to McCain, because Obama made Bush a pet name for him.) We can put a timeout exception to end it.
Let’s first make a troublesome function, one that sometimes runs overtime.
from time import sleep
def f(x):
""" x can be any integer.
But when x is a even number, it takes x seconds to finish;
when x is an odd number, it takes one second.
When x=2, it causes an error/exception.
"""
sl = x if (-1)**x >0 else 1
print("Start running with x={} and sleep={}".format(x,sl))
sleep(sl)
try:
print(" finished with x={} and sleep={}, result={}".format(x, sl, 1 / (x-2)))
return x
except Exception as e:
print('\n\nCaught exception {} in worker thread (x = {:d}):'.format(e, x))
return None
And, let’s make use of a 2-core CPU by using Python’s multiprocessing. Run f(x) parallelly, and collect results as a list. And every child-process is allowed to run for at most 5 seconds. In the end, we collect the result and do some analysis (that’s not the job of this post, though).
import multiprocessing
if __name__ == '__main__':
with multiprocessing.Pool(2) as pool:
async_results = [pool.apply_async(f, (i,)) for i in range(20)]
results_collection=[]
for async_res in async_results:
try:
this_res = async_res.get(timeout=5)
results_collection.append(this_res)
except Exception as e:
print("Exception: {}".format(e))
results_collection.append(None)
pass
print(results_collection)
#Removing unsuccessful ones
results_collection = [r for r in results_collection if r !=None]
print(results_collection)
The outputs:
[0, 1, None, 3, 4, 5, 6, 7, None, 9, None, 11, None, 13, None, 15, None, 17, None, 19]
[0, 1, 3, 4, 5, 6, 7, 9, 11, 13, 15, 17, 19]
The first line of output has 20 elements. The return value of f(x) for x in range(20). Some are None (x=2, 8, 10, 12, 14, 16, 18) because it either had an error or was timed out.
And the final result is ready for analysis next step: [0, 1, 3, 4, 5, 6, 7, 9, 11, 13, 15, 17, 19]
How it runs live:
The code in GitHub:
The code looks too simple. Why would I bother writing a post in my blog? Well, to me, yesterday it was not this simple. I tried a few other ways. They didn’t work. The worst case was, my workstation was even frozen, and I cannot run any command even in bash. There was an error message from the OS: “-bash: fork: retry: Resource temporarily unavailable.” And I googled a way out… “exec killall python3”
Machine Learning sounds like a cool thing. I have wanted to learn it for some while, but with little progress. Perhaps a lack of motivation is a problem.
Today I have a task at hand that may need to use it. I guess learning by doing could solve my lack of motivation issue.
Here are a few things I would like to check:
https://www.groundai.com/project/a-supervised-learning-approach-for-heading-detection/1
This paper is so cool. It compares several classifiers, their timing, and precision in doing the classification. And found that Decision Tree is among the best in precision.
Another way this paper is very cool with is, its raw input is PDF, and it converts it to HTML with formats, and then uses HTML format tag as input for classifying!
https://www.datacamp.com/community/tutorials/decision-tree-classification-python
https://scikit-learn.org/stable/modules/tree.html
from sklearn import tree
clf = tree.DecisionTreeClassifier()
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = clf.fit(X, Y)
clf.predict([ [2., 2.], [-0.1, -0.1], [1,2]])It runs. The result makes sense too: array([1, 0, 1])
Python is easy to code. But it may not be the most efficient one that runs on a CPU.
CPython can drastically improve the execution speed. In a project of mine, it runs at least four times as fast as before.
Python is slow because it runs on an interpreter. Line by line, the Python interpreter translates in real time the python code into machine code and run it.
CPython changes the situation. It converts the Python code you write into a C code, compiles it into a library, and now one can import it back into Python just like a normal python package.
In the example below, let me share how to use CPython. The example is one from the source code shared by a JAR paper by Brown, Crowley, and Elliott (2020). I slightly updated their approach to fit my needs (or my laziness).
Brown, Nerissa C., Richard M. Crowley, and W. Brooke Elliott. “What are you saying? Using topic to detect financial misreporting.” Journal of Accounting Research 58, no. 1 (2020): 237-291.
Suppose you have a function parse() to run, which is written in Parse.py
Do the following:
# cython: language_level=3
# The above comment is for CPython to read. DO NOT REMOVE.
from distutils.core import setup
from Cython.Build import cythonize
import os, shutil
#Provide the file name of your original Python code:
python_file = "Parse.py"
#Automatically copy it to make a .pyx file, and set up if os.path.isfile(python_file+"x"): os.remove(python_file+"x") shutil.copy(python_file, python_file+"x") setup( ext_modules = cythonize(python_file+"x") )python Parse_Setup.py build_ext --inplace
from Parse import parse
parse()
python Parse_Run.py
Here (URL) someone compares the speed of pure python with numpy and with Cython. It seems that Numpy are x31 as fast, Native Cython is x24 as fast… Noting that Numpy is also running C in the backend, this is reasonable.
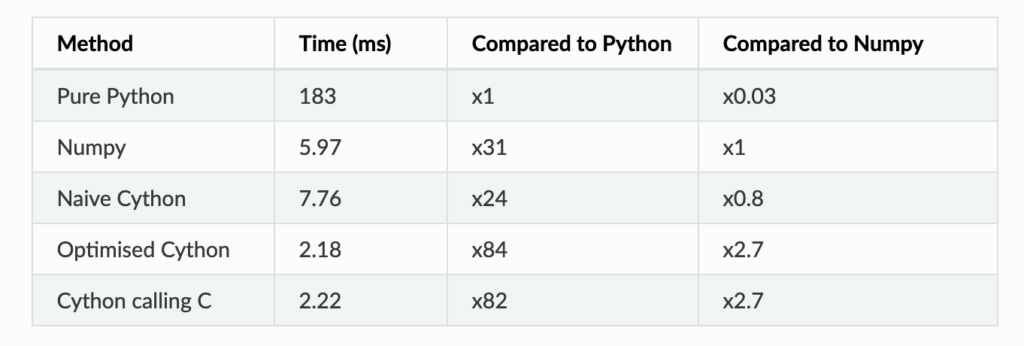
I tried a minimal example of using the Monte Carlo method to estimate \PI, which uses numpy.random, and the result is…. disappointing. CPython only makes it slowlier…
| real time | 2 core user time | |
| Python + Numpy | 2m37s | 5m10s |
| Python + Numpy + CPython | 2m41s | 5m13s |
I may need to build a minimal example to compare the performance with and without CPython for RegEx, the only thing whose speed bothers me.